[1] R. Szeliski. Computer Vision: Algorithms and Applications[M]. 2010.
[2] 塞利斯基, 艾海舟. 计算机视觉:算法与应用[M]. 清华大学出版社, 2012.
Book overview 本书概述
作者给出的章节结构图如下
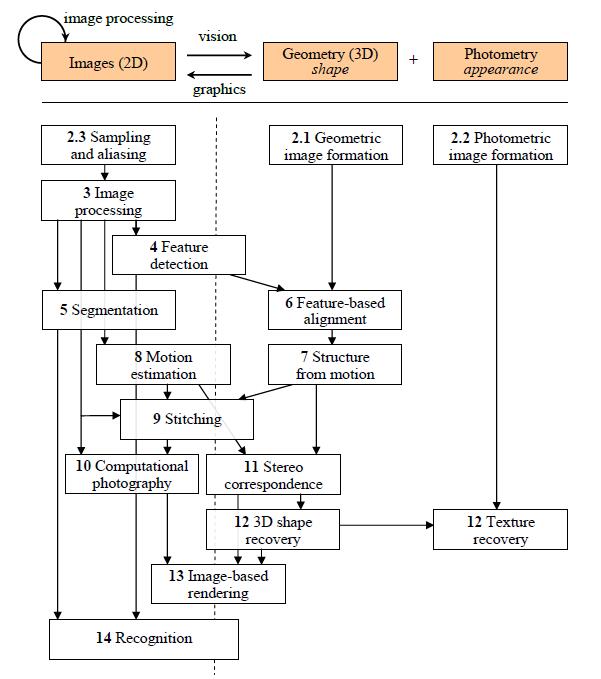
从左至右分别是基于图像(2D)、基于几何形状(3D)和基于光度学(表现)。从上至下,建模和抽象的层次在增加,下层的方法基于上面所提的算法基础上发展。其中的处理和依赖关系不是严格有序的,还存在其它精细的依赖和关系。横向排列的主题也应辨证看待,因为多数视觉算法涉及至少两种不同的表达。
第二章是我们所看到和捕捉的图像的形成过程的概述。图像的形成有三个主要的组成部分。2.1节Geometric image formation处理的是点、线、面,以及如何借助投影几何和其它模型(including radial lens distortion,径向透镜畸变)将它们映射到图像上。2.2节Photometric image formation包括辐射测量学(radiometry)和光学(optics)。2.3节介绍了传感器如何工作,包括采样、混叠、色彩感知和摄像机内的压缩。
第三章涉及图像处理,包括线性和非线性滤波(3.3节)、傅里叶变换(3.4节)、图像金字塔和小波(3.5节)、图像卷绕的几何变换(3.6节)以及一些全局优化方法例如正则化(regularization)和MRFs(Markov Random Fields,马尔可夫随机场)(3.7节)。与图像处理不同的是,计算机视觉更注重优化方法的使用。第三章还介绍了一些应用,例如无缝图像拼接和图像复原。
第四章主要介绍特征检测和匹配(feature detection and matching)。特征点的匹配是当前很多3D重建技术和识别技术的基础,也是后续第6、7、9、14章节的基础。这里还介绍了边缘和直线检测。
第五章主要介绍区域分割技术(region segmentation technique),包括活动轮廓检测(active contour detection)和跟踪(tracking)。分割方法包括自顶向下(split)和自底向上(merge)方法、均值移位方法(mean shift)和各种基于图的分割方法(graphbased segmentation approaches)。这些方法广泛应用于performance-driven animation(表演驱动动画?)、交互式图像编辑(interactive image editing`)和识别(recognition)。
第六章讲几何配准(geometric alignment)和摄像机标定(camera calibration)。6.1节用线性或非线性最小二乘法(linear or non-linear leastsquares)解决基本的基于特征的配准问题。这里还引入了其它的概念,例如不确定性加权(uncertainty weighting) 和鲁棒回归(robust regression)。6.2节介绍了基于特征的配准可以应用在3D姿态估计问题(3D pose estimation)上,6.3节则讲了这种配准方法如何用作摄像机内标定的构成部分。还介绍了活页动画的照片配准、手持摄像机做3D姿态估计、单视图恢复建筑模型等应用。
第七章的主题是structure from motion(运动结构),包括3D照相机运动的即时恢复(simultaneous recovery of 3D camera motion)和收集跟踪2D特征来重建3D场景结构(3D scene structure from a collection of tracked 2D features)。7.1节从较简单的3D point triangulation(3D点三角剖分)开始,即已知摄像机位置时如何根据匹配的特征重建3D点。然后介绍了two-frame structure from motion的代数方法(algebraic techniques)和鲁棒采样方法(robust sampling techniques,例如RANSAC,其特征匹配可以容忍部分错误)。第七章的第二部分描述了多帧运动结构,包括7.3节的factorization(因子分解),7.4节的光束平差法(bundle adjustment)以及7.5节的限定运动和结构模型(constrained motion and structure models)。这里还给出了运动结构在视觉变形(view morphing)、稀疏3D模型重建(sparse 3D model construction)、移动匹配(match move)中的应用。
第八章回到处理图像亮度,也就是基于亮度的稠密运动估计(dense intensity-based motion estimation,optical flow)。8.1节从最简单的运动模型translational motion(平移运动)开始,介绍了分层运动估计(hierarchical motion estimation)、傅里叶方法和迭代求精(iterative refinement)。接着在8.2节中介绍了可用于补偿摄像机的旋转和聚焦的参数化运动模型(parametric motion models),以及仿射和平面透视运动。在8.3节中将其推广为基于样条的运动模型(spline-based motion model)。最终在8.4节推广到通用逐像素的光流(general per-pixel optical flow),包括8.5节介绍的layered and learned motion models。这些技术广泛应用于自动变形(automated morphing)、帧插值(frame interpolation)和基于运动的用户界面。
第九章关注图像拼接,也就是大的全景图和合成图的形成。9.1节介绍了各种可能的运动模型,包括平面运动(planar motion)和纯摄像机运动(pure camera rotation)。9.2节介绍全局匹配(global alignment),这是光束平差法的特殊情况。接着介绍全景图识别(panorama recognition),这是一种自动识别哪些图像实际形成了重叠的全景图的技术。最后在9.3节介绍了图像合成(image compositing)和混合(blending)主题,主要关注于选择哪些像素并将它们混合在一起以掩盖曝光差异的问题。
这里作者说到图像拼接可以与前面所涉及的图像卷绕和特征识别相结合,应用于白板和文档扫描、视频摘要、360度球面全景以及将重复镜头混合在一起的交互式照片蒙太奇。
第十章介绍了计算摄影学的其它应用,即从一张或多张照片里创建新的照片,通常基于10.1节所介绍的基于图像形成过程的精细建模和校准(careful modeling and calibration of the image formation process)。计算摄影学方法包括10.2节所介绍的归并多曝光照片(multiple exposures)创建高动态范围图像、10.3节的通过模糊去除和超分辨率方法(super-resolution)来提高图像分辨率、10.4节的图像编辑与合成(compositing)操作。10.5节还介绍了纹理分析(texture analysis)、图像合成(synthesis)、图像修复(inpainting)、非真实感渲染(non-photorealistic rendering)。
第十一章关注立体视觉匹配(stereo correspondence),它是摄像机位置已知下的运动估计问题的特殊情况。这使得立体视觉算法可以在更小的匹配空间中搜索,产生稠密深度估计,进而转化成可见表面模型(visible surface models)(11.3节)。11.6节还介绍了多视角立体视觉算法(multi-view stereo algorithms),可以呈现真实3D表面而不是单一深度图。立体视觉匹配的应用有头部和凝视追踪(head and gaze tracking)、基于深度的背景替换(depth-based background replacement)。
第十二章介绍了一些其它的3D形状和外观建模技术,包括经典的shape-from-X techniques,例如12.1节的从阴影(shading)到形状、从纹理(texture)到形状、从焦点(focus)到形状、从光滑的遮挡轮廓(occluding contours)到形状和12.5节的从剪影(silhouettes)到形状。12.2节介绍了一种主动测距的方法(active range finding)可以取代上述被动计算机视觉技术。将模式化光投影到场景上然后通过三角剖分重建3D结合体。这些3D表达处理通常设计插值(interpolating)或几何简化(simplifying the geometry),以及12.4节介绍的表面集合点集(surface point sets)等其它方法。12.6节探讨了基于图像的3D建模的三种特殊应用:建筑学、人脸和人体。它们使用模型重建对感知数据进行参数化拟合。12.7节讨论外观建模(appearance modeling),包括估计纹理度(texture maps)、反照度(albedos),以及BRDF方法(bi-directional reflectance distribution functions,完整双相反射分布函数)。
第十三章讨论基于图像的绘制方法,例如13.1节的视角插值(view interpolation),13.2节的分层深度图像(layered depth images),子画面(sprites)和图层(layers),13.3节的光场(light fields)和照度图(Lumigraphs)的一般框架,和13.4节的如环境影像形板(environment mattes)的高阶场。第十三章还介绍了基于视频的渲染,它是基于图像渲染在时间上的扩展。内容包括基于视频的动画(video-based animation)、周期性视频转化为视频纹理(periodic video turned into video textures)和从多个视频流重建3D视频(3D video constructed from multiple video streams)。主要应用有视频去噪、变形和360度视频导览。
第十四章介绍识别(recognition)。14.1和14.2节介绍人脸检测和识别技术,然后在14.3节寻找和识别特定物体。接着在14.4节介绍了宽泛类属的识别(recognition of broad categories)并在14.5节介绍了场景内容(scene context)在识别中的作用。